



Approaching the problem
Problem
Do you want to predict a category (classification), a quantity (regression), an anomaly (anomaly detection), finding a relationship between variables in different databases (association rules or recommendation) or do you want to discover structure in unexplored data (clustering)?
Available resources
The quantity, quality, variety of data available play an important role. Typically, it is said that if you have more than 1,00,000 data points you can apply almost all algorithms. (SAP Conversational AI, n.d.) The number of classes labeled data matter.
Based on Sci-kit learn minimum 50 samples are needed to start with ML approach.[1]
Constraints
What is your data storage capacity? Depending on the storage capacity of your system, you might not be able to store Gigabytes of classification/regression models or gigabytes of data to clusterize. This is the case, for instance, for embedded systems.
Does the prediction have to be fast? In real-time applications, it is obviously very important to have a prediction as fast as possible. For instance, in autonomous driving, it’s important that the classification of road signs be as fast as possible to avoid accidents, obviously…
Does learning have to be fast? In some circumstances, training models quickly are necessary: sometimes, you need to rapidly update, on the fly, your model with a different dataset. Two also very important aspects we, enthusiastic developers, tend to forget is the maintainability of the solution we choose, and, communication.
Maintainability: it is sometimes more judicious to go for a simpler solution giving correct results, instead of a very sophisticated solution you’re not 100% confident with giving slightly better results. We might not be able to easily update the solution or correct a bug in the future.
Communication: Developers, are sometimes working with non-developers. For some projects, it is sometimes necessary to expose your solution to people of other professions. In this case, it might be judicious to go for an ML solution that is more suitable for a layman.
Can Machine Learning solve this problem?[2]
]](https://cdn-images-1.medium.com/max/2000/1*T643niQJlKeYRYb5DpmVQQ.png) Traditional programming vs ML approach [source]
Traditional programming vs ML approach [source]
Is it an automation problem or learning problem?
Hedge funds automatically filtering out bad data in the form of a negative value for trading volume, which can’t be negative is an automation problem.
On the other hand, encoding human language into a structured dataset is something that is just a tad too ambitious for a straightforward set of rules
When automation rules become too complex then ML comes into the picture. ML will find patterns on deciding.
How to decide if a problem is an ML problem?
Any problems those: [3]
Require prediction rather than causal inference and
Are sufficiently self-contained, or relatively insulated from outside influences.
The first means that you are interested in understanding how, on average, certain aspects of the data relate to each other, and not in the causal channels of their relationship. Keep in mind that the statistical methods do not bring to the table the intuition, theory, or domain knowledge of human analysts.
The second means that you are relatively certain that the data you feed to your learning algorithm includes all there is to the problem. If, in the future, the thing you’re trying to predict changes unexpectedly — and no longer matches prior patterns in the data — the algorithm will not know what to make of it.
Examples of good machine learning problems include predicting the likelihood that a certain type of user will click on a certain kind of ad or evaluating the extent to which a piece of text is like previous texts you have seen.
Bad examples include predicting profits from the introduction of a completely new and revolutionary product line or extrapolating next year’s sales from past data when an important new competitor just entered the market.
Error acceptance level[4]
Every human makes mistakes, and every algorithm is error-prone, too. For all but the simplest of problems, there will be times when things go wrong. The machine learning prediction engine with getting things right on average but will reliably make mistakes. Mistakes will happen, and they will happen most often in ways that you cannot anticipate.
Evaluate the extent to which you can allow for exceptions or statistical errors in your process. Is your problem the kind of problem where getting things right 80% of the time is enough? Can you deal with a 10% error rate? 5%? 1%? Are there certain kinds of errors that should never be allowed? Be clear and upfront about your needs and expectations, both with yourself and with your solution-provider. And once both of you are comfortable on the same page, go ahead. Armed with knowledge, understanding, and reasonable expectations, you are set to reap the benefits of machine learning. Just please be patient.
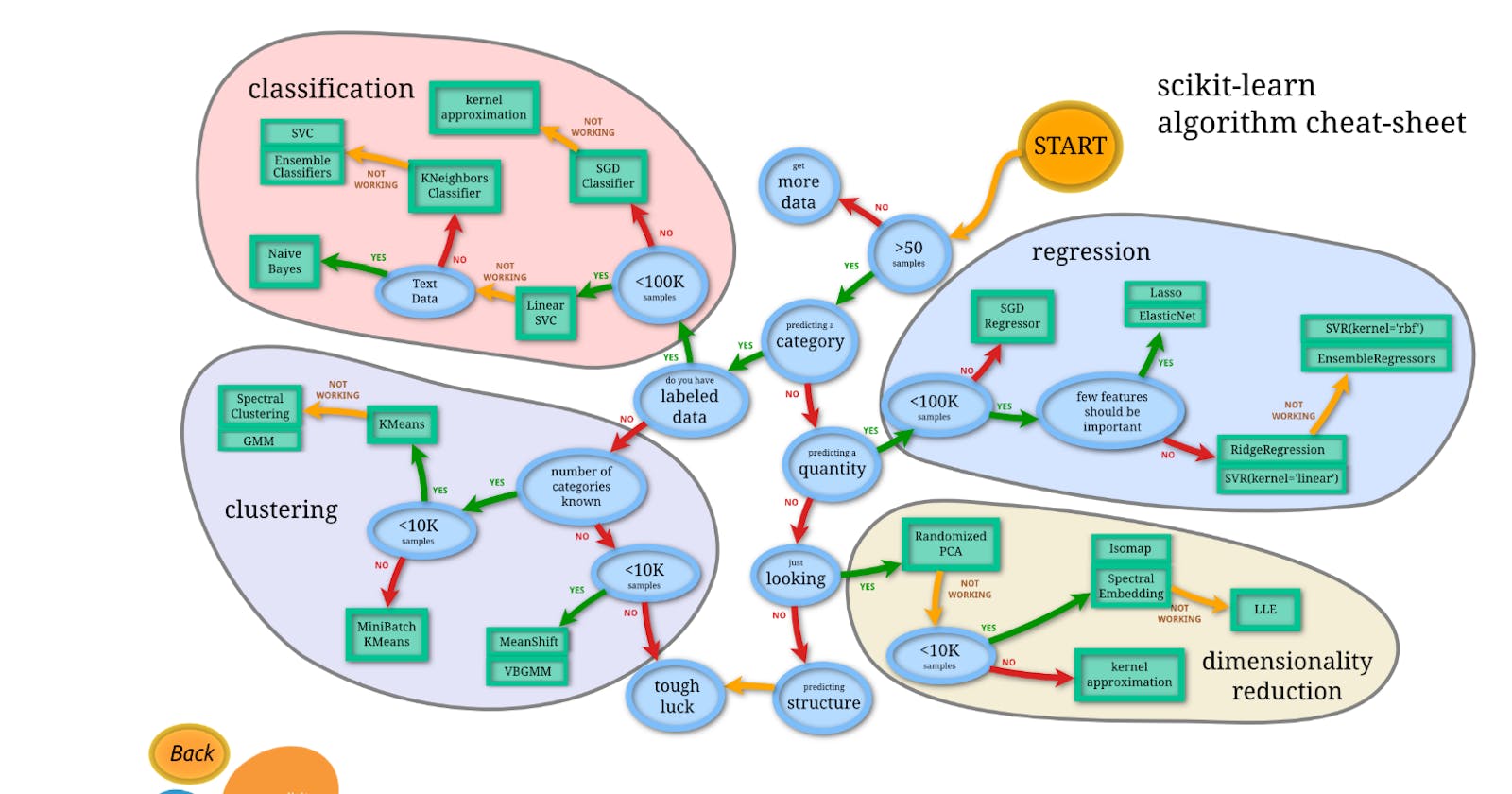
Possible Algorithms
](https://cdn-images-1.medium.com/max/3150/1*AotLqUBWRytEpzQBol9BxQ.png) Source: Sci-kit learn library of Python
Source: Sci-kit learn library of Python
 A list of ML algorithms
A list of ML algorithms
Once the problem statement is defined, the minimum dataset requirement tick marked, and you have decided to go with the ML approach, you need to identify a class of algorithms out of the following lists:
Supervised
Classification
Regression
Unsupervised
Clustering
Recommendation or Association rule
Supervised ML
If you have more than 50 samples[5] of labeled data and a defined output requirement you can start with Supervised Learning.
Based on the target variable the algorithm needs to be determined as a classification or regression. Before going further data analysis and feature selection need to be done as described in these articles.
Classification
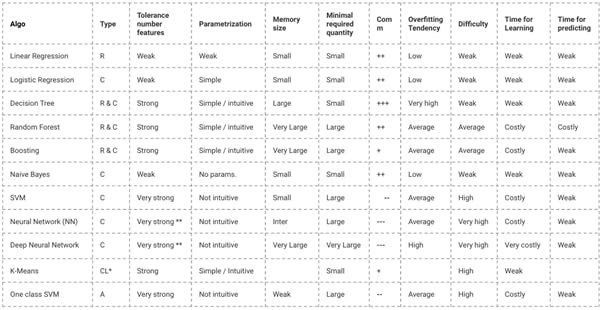
](https://cdn-images-1.medium.com/max/2000/1*CwfV0qrMx_d0xrhlrKygcQ.png) Source: http://www.cs.cmu.edu/~aarti/Class/10701/MLAlgo_Comparisons.pdf
Source: http://www.cs.cmu.edu/~aarti/Class/10701/MLAlgo_Comparisons.pdf
If the target variable(s) is discrete (categorical/nominal/ordinal) classification algorithm need to be used.
Logistic Regression
Naïve Bayes classifier
Support vector machines
Decision trees
Boosted trees
Random forest
Neural networks
K-Nearest neighbors
How to select the right classification algorithm?[6]
Logistic regression is the de facto algorithm to start with solving classification problems. It is fast and explainable. However, it works only for binary classification and does not accept null values in any features. Naïve Bayes can outperform Logistic regression if the independent features are not correlated to each other. It can work with a large number of data sets.[7]
SGD (Stochastic Gradient Descent) can handle a large number of input data sets with its pre-built various loss functions. It is very efficient for linear models. However, it requires many hyperparameters and sensitive to feature scaling.
K-nearest neighbors (KNN) it’s effective if training data is huge and noisy data does not affect it. However, you need to determine the value of K and the computation cost is high as it needs to compute the distance of each instance to all the training samples.
Decision trees are explainable and visualizable to business on the model’s outcome. There is a high chance of overfitting. It can be mitigated by using multiple DTs called Random Forest. RF works better than SVM (Support Vector Machine). However, RF takes more time for real-time prediction and difficult to explain.
As you have gone through these popular algorithms, there is no one-stop solution for all the ML classification problems. Depending on the data and business cases the algorithm needs to be chosen with trade-offs on various aspects. For e.g., if the business wants how the ML model concludes on an output result, Logistic regression or Decision Trees can be implemented. However, both come with their own disadvantages. There is always a trade-off on choosing the right algorithms.
Common practice: Based on the use case and data the probable similar algorithms are tested, and cross-validation is done to find the performance of each classifier. The best one gets chosen.
Regression
If the target variable(s) is continuous then regression algorithms need to be used. The common algorithms can be used:
Linear regression
Polynomial regression
Ridge regression
Lasso regression
ElasticNet regression
How to select the right regression model?
Data exploration is an inevitable part of building a predictive model. It should be your first step before selecting the right model like identify the relationship and impact of variables
To compare the goodness of fit for different models, we can analyze different metrics like the statistical significance of parameters, R-square, Adjusted r-square, AIC, BIC and error term. Another one is Mallow’s Cp criterion.
If the relationship between independent and dependent variables are linear then Linear regression needs to be used. In the case of non-linearity polynomial regression.
Regression regularization methods (Lasso, Ridge, and ElasticNet) works well in case of high dimensionality and multicollinearity among the variables in the data set.
Ensemble Learning
As you have seen different algorithms are specialized in different use cases. To maximize the result two or a more diverse set of algorithms can be combined to increase the accuracy and performance of the model. The Ensemble is the art of combining a diverse set of learners (individual models) together to improvise on the stability and predictive power of the model.[8] Some commonly used ensemble methods are bagging, boosting and stacking. [9]
Conclusion
Each ML algorithm has its own efficient place based on the received data. Depending on the use case the algorithm or estimator needs to change. There is no all-in-one estimator for every use case in the world. May there will be something in Auto-ML or more advanced methods. However, we have to remember the strengths and weakness of the estimators, which can set our path during EDA (Exploratory Data Analysis).
References:
[1] https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
[2] https://cai.tools.sap/blog/machine-learning-algorithms/
[3] https://hbr.org/2016/11/how-to-tell-if-machine-learning-can-solve-your-business-problem
[4] https://hbr.org/2016/11/how-to-tell-if-machine-learning-can-solve-your-business-problem
[5] https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
[6] https://www.analyticsindiamag.com/7-types-classification-algorithms/
[7] http://blog.echen.me/2011/04/27/choosing-a-machine-learning-classifier/
[8] https://www.analyticsvidhya.com/blog/2015/08/introduction-ensemble-learning/
[9] https://www.toptal.com/machine-learning/ensemble-methods-machine-learning