



Business requirement
There are data coming to my system from multiple sources MySQL, logs and including occasional files uploads.
The data comes both static and dynamic way i.e. real-time data as well as batch data.
I have to build a system which combines all these data inputs and prepares analytics over it.
PySpark is just a Python wrapper around Apache Spark which is written in Scala programming language. Why should I use PySpark instead of Pandas, Hadoop or Dask?
Pandas

Pandas is good for:
Tabular data with millions of rows
It has been for quite a bit of time and has much more capabilities and features compared to PySpark.
In fact, for exploratory data analysis (EDA) it has been one of the best choices.
But, where does Pandas give up?
My data is stored across several computers in a distributed manner
My computer does not have the processing capability to process large amounts of data using Pandas.
My data comes in real time streaming way and as well as batches. I have to analytics by combining
In these cases, we have to look away from Pandas. My favorite Pandas is not enough for my increasing size and type of data.
Hadoop

I googled and found Hadoop is a well-established tool to handle my increasing growth of data. Few things which Hadoop is good for:
It’s a big data platform; distributed system
Hadoop has compute system, MapReduce and storage system, HDFS.
Can work by integrating cheap commodities together
However, it does not fit my requirement:
Hadoop stores the incoming data in its HDFS system which is good for latency. However, its performance is not par with Spark, which stores data in memory. Therefore, Spark is faster than Hadoop. That makes the on-prem Spark deployment costly also.
In another case, HDFS recommends a file size of 128MB to store data at a time. Smaller units of data with repetitive write operation are not efficient, which affects my real-time data processing requirement. More details on this issue can be found here, here and here.
Dask

Dask provides advanced parallelism for analytics, enabling performance at scale for the tools. It is written in Python on top of Pandas. Therefore, in addition to the features supported by Pandas it also has:
lightweight and can run on both single and distributed cluster.
Dask provides parallel arrays, dataframes, machine learning, and custom algorithms which are easier to integrate with existing Python code.
Dask acts better in time series, random access, and other complex computations than Spark.
However, it has some limitations as well:
It has not implemented all the functionalities of Pandas.
Can not integrate with Hadoop, no wrapper yet with non-python languages.
It has fewer features than PySpark.
Apache Storm

Apache storm is another alternative for Spark. Some features of Apache Storm include:
Zookeeper, Kafka and ZeroMQ are already in-built.
Throughput is 10k records per second in Storm but better in Spark with 100k records per second with higher latency too.
The same code can be used in both batch and stream processing in Spark, which is of great advantage to me.
Apache Flink

Apache Flink is also another one of the best alternatives to Spark. Some features include:
Continuous stream processing instead of micro-batches as of Spark. Although this does not matter a lot.
Window criteria are time-based in Flink, but records based or custom based in Spark. This does not matter in my use case.
Memory management is automatic in Spark. However, it needs to be configured in Flink.
Conclusion

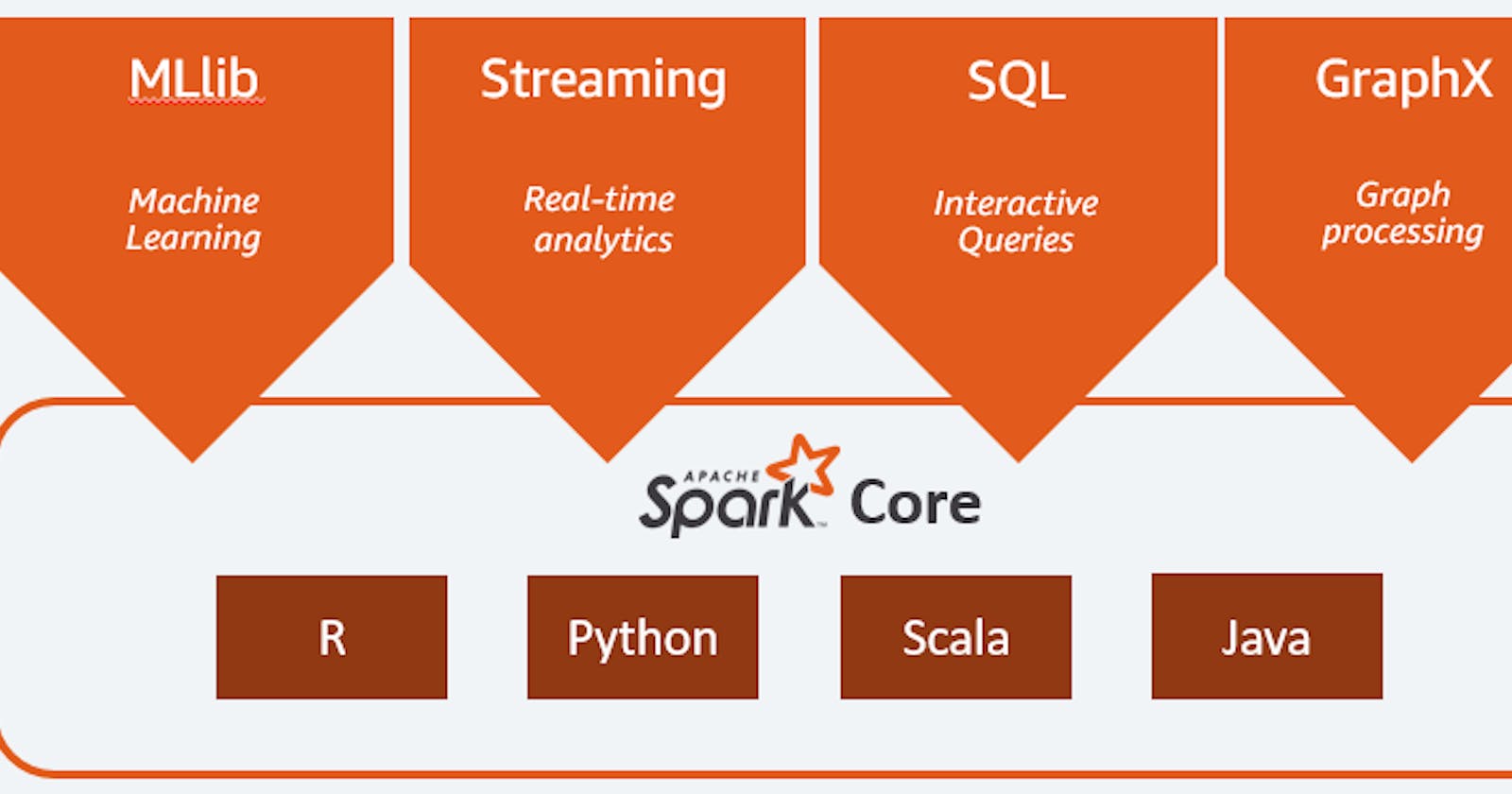
It is a tough decision to choose in between Dask and PySpark. However, In addition to other differences, PySpark is an all-in-one ecosystem which can handle the aggressive requirements with its MLlib, Structured data processing API, GraphX will definitely of help. Hadoop data can be processed with PySpark, so it will not be of any problem. Storm and Flink have got discarded due to their other differences.